

The Fast Privacy-preserving RFID Authentication Protocol Based on LPN
-
摘要: 大多数基于LPN问题设计的RFID协议主要侧重于身份认证协议,较少涉及隐私识别与认证,为解决此问题,对现有的基于LPN问题设计的认证协议与实现隐私识别的认证协议进行系统性的分析,总结这类协议的优点与存在的缺陷,利用RFID系统中拥有的大型存储设备数据库和伪随机数产生器,设计了一个基于LPN的具有快速识别的RFID隐私认证协议(FIP_Auth). 此外,将FIP_Auth协议与Tree-LSHB+、BAJR、MMR协议进行了效率与安全性的比较. 研究结果表明:FIP_Auth协议具有识别速度快、可证明的隐私性和认证性等优点,并且具有良好的可扩展性.Abstract: Most LPN-based RFID protocols focus on authentication but rarely consider privacy. The existing protocols for RFID based on LPN problem and privacy preservation are systematically analyzed and their advantages and disadvantages are summarized. Using the large storage device database in the RFID system and the pseudorandom generator, an LPN-based RFID privacy authentication protocol with fast identification is designed to ensure that privacy is not leaked during the authentication of the protocol. The efficiency and safety of the designed protocol are compared with that of the Tree-LSHB+ protocol, BAJR protocol and that of the MMR protocol. The research indicates the protocol has fast identification, provable security and authentication and good scalability.
-
Keywords:
- RFID /
- LPN /
- pseudorandom generator /
- fast identification /
- forward privacy
-
无线射频识别(Radio Frequency Identification,RFID)技术是一种在开放性环境中自动识别对象的技术,因其成本低廉、部署简易而被广泛地应用于支付系统、供应链管理和产品防伪等领域. RFID技术的广泛应用需要保证系统中标签的低成本,但标签的低成本限制了其计算能力,也为保证阅读器与标签之间的通信隐私安全增加难题. LPN(Learning Parity with Noise)[1]是计算复杂性领域的一个困难问题,其所涉及的计算只是进行简单的异或操作,对计算量和存储量的要求低,适用于标签这种资源受限的设备.
在RFID研究领域中,大量工作致力于研究轻量级的RFID认证协议,其中一类是基于LPN问题设计的认证协议,包括HB协议[2]、HB+协议[3]、HB#协议[4]、Auth协议[5]、Auth#协议[6]、LPNAP协议[7]和Auth-Hash协议[8]等. 上述这类基于LPN问题设计的协议具有结构简单、抗量子攻击和计算复杂度低等优点,但该类协议[2-8]只提供认证性,不具备隐私安全性.
隐私安全性和识别是RFID系统的2个主要目标[9],大多数RFID协议为了保证隐私性而降低识别效率. 阅读器搜索系统中所有的标签来识别单个标签,实现了隐私识别. 但是在大型RFID系统中,对每个标签识别执行线性搜索,尤其是在需要同时识别多个标签的应用中可能是一项繁琐的任务,并且可能导致拒绝服务攻击. 因此,对于一个实用的RFID系统,必须设计更加快速的识别方案.
为了提高识别效率,学者们[10-13]以树型结构存储标签,将识别效率提高至对数级别,但是这类基于树型结构设计的协议有2个缺点:(1)在无线信道中需要进行大量的通信;(2)一旦某个标签的信息泄露了,就会泄露其他未被破解的标签的信息,无法保证标签的隐私性. 由于树型结构无法保证标签的隐私性,ALOMAIR等[14]基于hash函数,设计了识别速率达到O(1)的BAJR协议,且保证了隐私安全,但是该协议使用hash函数,使得标签门电路复杂,无法实现低成本. 为了实现标签的低成本,MAMUN等[15]提出了基于LPN设计且识别效率达到O(1)的MMR协议,并证明该协议能抵抗一般中间人攻击并实现隐私安全. 由于MMR协议用于更新索引的值在上一次认证过程中会作为第二轮响应信息发送给阅读器,攻击者通过比对信息就能将标签的2次行为联系在一起,因此,MMR协议不具备隐私性.
本文借鉴MMR协议的设计思路和SFP(Simple and Forward Private)通用协议[16]构造的设计方法,提出了具有快速识别的隐私保护认证协议(Fast Identification and Privacy-preserving Authentication Protocol,FIP_Auth):利用基于LPN问题构造的伪随机数发生器和大型存储设备数据库设计FIP_Auth协议,实现标签的低成本,并达到快速识别和保证隐私性的目的.
1. 预备知识
1.1 符号说明
Z2表示有限域{0, 1},有限域{0, 1}*表示任意长度的二进制比特串的集合,对于{0, 1}*中的元素,有时看成比特串,有时看成向量,具体依上下文而定. k2表示Z2上的k维线性空间;X∈Zl×n2是l×n的二进制矩阵,XT表示X的转置矩阵;x∈Zl2是长度为l的二进制向量,|x|表示x的长度,wt(x)表示x的汉明重量;r$←Z2l2表示从Z2l2中均匀抽样出一个二进制向量r;x↓a表示与向量a相关的x的子向量:对于向量x、a,如果a[i]=0, 则删除x[i], 否则保留x[i] (例:x=(1, 1, 0, 0, 1, 1),a=(1, 1, 0, 1, 0, 0),则x↓a=(1, 1, 0));Ω表示Z2l2中汉明重量为l的所有向量的集合;Berτ表示参数为τ的贝努利分布(τ∈[0, 1/2]), e←Berτn表示从贝努利分布抽样出的n维二进制向量;符号"||"表示2个比特串的连接,也可表示2个向量的连接(例:a=(0, 1, 0, 0),b=(1, 0, 0, 1),则a||b=(0, 1, 0, 0, 1, 0, 0, 1));Un表示在{0, 1}n上随机变量的均匀分布.
1.2 困难性问题
定义1[17] (LPN问题)假设e←Berτn,wt(e)<τn,噪声参数τ∈[0, 1/2],x←Z2l2,R←R$←Z2l×n2,给定τ、R以及r=RT⋅x⊕e,LPN问题要求找到x′∈Z2l2,使得wt(r⊕RT⋅x′)<τn. LPN假设表明:在给定τ、R、r的情况下,攻击者无法在多项式时间内恢复x.
定义2[18] 一个伪随机数产生器(Pseudorandom Generator,PRG)是一个确定性函数G:{0, 1}*→{0, 1}*,需要满足以下2个条件:
(1) 拉伸:存在一个拉伸函数h:N→N,对所有的n∈N, 有h(n)>n, 且对所有的x∈{0, 1}*,有|G(x)|=h(|x|);
(2) 伪随机性:集合{G(Un)}n∈N、{Uh(n)}n∈N是计算不可区分的.
当h(n)=n+Ω(n)时,G是线性拉伸的伪随机数产生器(Linear-stretch Pseudorandom Generator,LPRG). 默认G是多项式时间可计算的.
定义3[2] (可忽略函数)函数neg(n)如果满足:对于任意常数c>0, 存在足够大的n,使得neg(n)<n-c,则称neg(·)是可忽略函数.
1.3 RFID系统
一般地,RFID系统主要由标签、阅读器和后端数据库三部分组成. 标签内存储标签与阅读器认证的信息及保护标签自身隐私的信息,后端数据库存储系统中所有标签的信息. 一般认为标签与阅读器之间的通信是不安全的,阅读器与后端数据库之间的通信是安全的. RFID系统的工作流程如下:
(1) 阅读器通过天线发射无线电载波信号;
(2) 标签进入阅读器的工作范围后,将其内部信息通过天线发送出去;
(3) 阅读器对来自标签的信息进行处理,将结果传到后端数据库;
(4) 后端数据库对接收到的信息进行处理,将结果返回给阅读器.
1.4 认证协议及其安全性
认证协议是指在阅读器和标签之间执行的交互式协议. 标签的拥有者使用标签向阅读器证明自己的身份,阅读器反馈认证结果. 在RFID系统中,阅读器与标签通过无线信道通信,该信道是不安全的,易遭受各种安全攻击,主要有被动攻击、主动攻击、中间人攻击和异步攻击等. 其中,异步攻击指攻击者可以阻断协议通信的进行,使标签和阅读器处于异步状态,并使标签将来的身份验证变得不可能.
此外,由于低成本的标签不具备任何防篡改的能力,攻击者试图通过破解标签来获得其内部状态信息,进而追踪标签之前的通信隐私. 前向隐私指的是攻击者破解了某个标签,但是攻击者不能跟踪该标签未被破解之前的所有通信隐私信息. 准确地说,前向隐私由在RFID系统中有攻击者A参与的前向隐私游戏GameA来确定,方法如下:先利用前向隐私游戏GameA来模拟现实的RFID攻击环境,然后根据游戏中2个标签行为的不可区分性来说明2轮通信的RFID认证协议的前向隐私安全.
前向隐私游戏GameA由2个阶段组成,GameA中的攻击者A是由算法A1和算法A2组成. 第一阶段,算法A1初始化RFID系统,并且可以随意调用预言机O1、O2和O3,总共调用次数不超过q次,输出2个未被调用过O3预言机的标签T0、T1和状态信息st,将这2个标签作为下一阶段的候选挑战标签. 第二阶段,首先,游戏选取一个随机数β$⟵{0,1};然后,把Tβ给攻击者作为挑战标签,算法A2可以对Tβ随意调用预言机O1、O2和O3来进行查询;最后,算法A2输出一个随机数β′,若β=β′,则表示攻击者A成功地攻击了RFID系统的前向隐私性.
GameA中涉及的3个预言机O1、O2和O3定义如下:
(1) Launch(R):使阅读器产生一个新的会话标识sid和协议中阅读器第一轮产生的消息m1,该预言机O1模拟窃听获取第一轮协议的通信消息;
(2) SendTag(sid, m1, T):该预言机O2模拟窃听篡改标签的计算和协议信息,输出第二轮的通信信息m2;
(3) Reveal(T):该预言机O3模拟破解标签,获取标签T的内部信息.
定义4[16] (前向隐私性)在前向隐私游戏GameA中,若不存在任意多项式时间攻击者A在时间t内以ε不可忽略的优势攻击成功,则称该RFID系统是前向隐私安全的.
2. FIP_Auth协议的设计方案
本节将基于LPN设计的伪随机数产生器G[19]应用于RFID系统中,并借鉴BAJR协议[14]在解决协议发生异步攻击的情况下识别效率是O(1)的方法,利用RFID系统中拥有的大型存储设备数据库设计具有快速识别的隐私保护认证协议(FIP_Auth),该协议的设计方案具体表述如下.
2.1 系统初始化FIP_Init
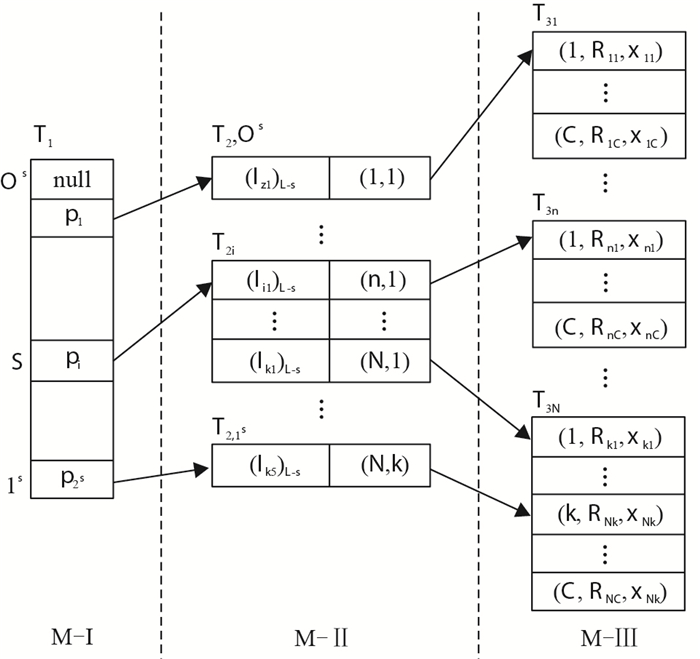
设N是系统中标签的总数,C是计数器计数的最大值,每个标签Ti存储其初始密钥对(Ri1, xi1),G1与G2为2个PRG函数,令函数G1(x)的输出长度为L,L>2l(标签密钥xi1的长度为2l). 对于每个标签Ti(i=1, 2, …, N)和每一个j(j=1, 2, …, C),将标签Ti存储的密钥信息xij作为伪随机数产生器G1的输入,计算数据库初始化所需要的索引值Iij=G1(xij),Iij表示第j次识别标签Ti时的索引;将标签Ti存储的密钥信息Rij作为伪随机数产生器G2的输入,G2(Rij)=xi, j+1||Ri, j+1用来更新标签Ti的密钥信息(Ri, j+1, xi, j+1). 为了方便,根据计算的所有索引值Iij建立数据库初始化所需的索引值表(图 1),其中第i行表示识别标签Ti所需要的索引信息.
![]() 图 1 RFID系统的数据库初始化所需的索引值表Figure 1. The table of index value required for RFID system database initialization
图 1 RFID系统的数据库初始化所需的索引值表Figure 1. The table of index value required for RFID system database initialization得到数据库初始化所需的索引值Iij后,根据该索引值构造RFID系统的数据库. 由于函数G1的输出长度为L,所以索引值Iij的长度为L,需要O(2L)的存储空间来存储数据库初始化所需索引值Iij.为了节省存储空间,将数据库分为3个逻辑部分M-Ⅰ、M-Ⅱ和M-Ⅲ. 具体构造(图 2)如下: (1)M-Ⅰ只含有1张表,表示为T1. 取L的高s位(s满足2s大小的存储是可行的)来构建T1表,则T1的高s位相同的索引值存储在M-Ⅱ的同一个小表中,T1的第i行存储高s位为i-1的所有索引值的低L-s位在M-Ⅱ中的表的位置. (2)M-Ⅱ由若干个小数据表组成,表示为T2i(i=1, 2, …, 2s).M-Ⅱ的表的每条记录包含2个域,第1个域是存储索引Iij的低L-s位,表示为(Iij)L-s;第2个域是一对指针(i, j),其中i表示M-Ⅲ中的第i张表,j表示该表中的第j行.(3)M-Ⅲ由N个大小为C的数据表组成,表示为T3i(i=1, 2, …, N).T3i的第i张表存储标签Ti的信息,这张表中的第j行表示标签在第j次识别时的内部状态信息(Rij, xij).
FIP_Auth协议的数据库结构与BAJR协议的数据库结构类似,但又有所不同. BAJR协议中总是阅读器与数据库先更新密钥信息,待标签对阅读器认证成功后,标签才进行密钥更新,数据库只需要存储标签当前认证成功后的密钥更新信息并且保存上一次认证通过(即当前进行认证)的密钥信息. 当发生异步攻击时,标签的当前密钥信息是存储在数据库中的,可以通过阅读器的认证. FIP_Auth协议的密钥更新是标签与数据库同时进行,而阅读器不需要密钥更新,因此,FIP_Auth协议的数据库M-Ⅲ需要预先存储标签的C条密钥信息. 当发生异步攻击时,因标签的C条密钥信息已存储在数据库中,标签的信息可以在数据库中找到使得阅读器可以对标签进行认证,达到异步攻击安全. 若某标签认证达到C次,则需要更新数据库M-Ⅲ中该标签未来的C条记录.
2.2 FIP_Auth协议的执行过程
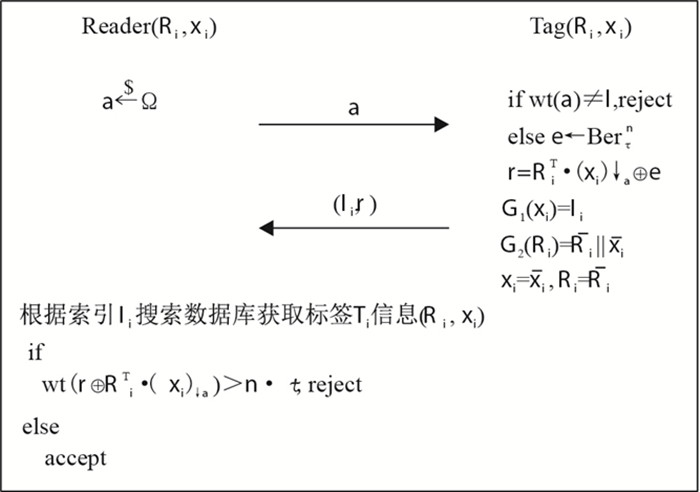
给定安全参数l, n∈N,每个标签Ti存储矩阵Ri∈Zl×n2和密钥xi∈Z2l2,Ri和xi在每次认证时进行更新.将每个标签的密钥xi作为伪随机数产生器G1的种子进行计算,计算结果作为建立后端数据库的索引,再以Ri为输入,计算G2(Ri),从而更新Ri和xi.阅读器同样具有计算G1和G2的能力,参数τ'=1/4+ τ/2是阅读器验证的阈值,其中τ是贝努利分布Berτ的参数. FIP_Auth协议的执行过程(图 3)如下:
![]() 图 3 RFID认证协议FIP_Auth的执行过程Figure 3. The implementation process of RFID authentication protocol FIP_Auth
图 3 RFID认证协议FIP_Auth的执行过程Figure 3. The implementation process of RFID authentication protocol FIP_Auth(1) 阅读器随机产生长度为2l的挑战向量a,其汉明重量为wt(a)=l,将其发送给标签.
(2) 标签首先判断wt(a)是否等于l,若不等于l,则拒绝,否则标签产生向量e←Berτn;然后计算r=RTi⋅(xi)↓a⊕e,G1(xi)=Ii和G2(Ri)=¯Ri‖, 并将(Ii, r)发送给阅读器;最后标签更新密钥xi=xi和矩阵Ri=Ri.
(3) 阅读器收到标签发来的信息(Ii, r),利用索引Ii搜索数据库:由Ii的高s位定位数据库M-Ⅰ的地址,该地址中存储了指向M-Ⅱ中小表的地址指针. 此时会出现3种情况:①指针指向空,说明没有相关标签信息;②指针指向的小表中只有1条记录,此记录的第2个域存储了指向M-Ⅲ中标签Ti信息(Ri, xi)的地址指针,此时可获取标签Ti信息(Ri, xi),并返回给阅读器,阅读器计算\mathrm{wt}\left(\boldsymbol{r} \oplus \boldsymbol{R}_{i}^{\mathrm{T}} \cdot\left(\boldsymbol{x}_{i}\right)_{\downarrow \boldsymbol{a}}\right),如果\operatorname{wt}\left(\boldsymbol{r} \oplus \boldsymbol{R}_{i}^{\mathrm{T}} \cdot\left(\boldsymbol{x}_{i}\right)_{\downarrow \boldsymbol{a}}\right)>n \cdot \tau^{\prime},则本次认证失败,否则认证成功;③指针指向的小表中有多条记录,此时需要将Ii的低(L-s)位与小表中的每条记录的第1个域值进行比较,找到相等值之后即可得到标签Ti信息的存储地址,阅读器得到标签信息,对标签进行认证.
由索引值Ii可知当前是第几次识别标签Ti. M-Ⅲ中除了存储标签Ti的实际信息(Ri, xi)外,还存储了该信息对应的识别次数j.每次在M-Ⅲ中获取标签信息时,都需要先判断j是否小于等于C. 若j=C,则需要对数据库进行更新操作,更新标签Ti的未来C次识别所需要的密钥信息. 更新操作如下:
首先,计算标签Ti未来所需的C个索引值. 根据当前数据库标签的信息(RiC, xiC),计算G2(Ri, k-1)=xik||Rik,索引Iik=G1(xi(k-1))(k=C+1, …, 2C). 然后,取索引Iik的前s高位,定位数据库M-Ⅰ的地址. 若该地址中存储的地址指针指向空,则在M-Ⅱ中新建一张表,以存储Iik的低L-s位和指向M-Ⅲ的地址(i, k-C);若不指向空,则遍历该小表,在小表末尾添加一条记录存储Iik的低L-s位和指向M-Ⅲ的地址(i, k-C). 此操作之后,原标签Ti存储在M-Ⅲ中的C条记录将被更新的C条记录所覆盖.
2.3 伪随机数产生器的构造
FIP_Auth协议中使用的伪随机数产成器G1和G2构造如下:取t、s是大于1的任意正整数,c、k1是实数. 令m1=k1r1,Mr1是\mathbb{Z}_{2}上每行包含1的个数至多为s的m1×r1的矩阵,g: \mathbb{Z}_{2}^{t m_{1} / c} \rightarrow \mathbb{Z}_{2}^{t m_{1}}是ε-biased产生器[20];定义函数G1,设L是G1函数输出长度,取k1=L/(2l(1+t)-tL(1+1/c)),r1=L/(k1+tk1), 则
G_{1}(x)=\left(\boldsymbol{M}_{r_{1}} \boldsymbol{x}_{r_{1}}+E\left(\boldsymbol{x}_{t \cdot m_{1}}\right), g\left(\boldsymbol{x}_{t \cdot m_{1} / c}\right)+\boldsymbol{x}_{t \cdot m_{1}}\right), 其中,\boldsymbol{x} \in \mathbb{Z}_{2}^{2 l},xr1是x的高r1位,xt·m1是x高r1位后的t·m1位,xt·m1/c是x的低t·m1/c位,E(xt·m1)=(Πj=1t(xt·m1)t·(i-1)+j)i=1m1,则G1:\mathbb{Z}_{2}^{2 l} \rightarrow \mathbb{Z}_{2}^{L}.
令m2=k2r2,其中k2是实数.Mr2是\mathbb{Z}_{2}上每行包含1的个数至多为s的m2×r2的矩阵集合;g: \mathbb{Z}_{2}^{t m_{2} / c}→\mathbb{Z}_{2}^{t m_{2}}是ε-biased产生器;取k2=(nc+c)/(nc-tn-2tc-2t),r2=(ln+2l)/(k2+tk2),定义函数G2为:
G_{2}(\boldsymbol{R})=\left(\boldsymbol{M}_{r_{2}} \boldsymbol{R}_{r_{2}}+E\left(\boldsymbol{R}_{t \cdot m_{2}}\right), g\left(\boldsymbol{R}_{t \cdot m_{2} / c}\right)+\boldsymbol{R}_{t \cdot m_{2}}\right), 其中, \boldsymbol{R} \in \mathbb{Z}_{2}^{l \times n},Rr2是R的高r2位,Rt·m2是R高r2位后的t·m2位,Rt·m2/c是R的低t·m2/c位,E(Rt·m2 = (Πj=1t(Rt·m2)t·(i-1)+j)i=1m2,则G2:\mathbb{Z}_{2}^{l \times n} \rightarrow \mathbb{Z}_{2}^{l \times n} \times \mathbb{Z}_{2}^{2 l}.
3. 协议分析
3.1 安全性分析
异步攻击是阻断FIP_Auth协议的第2轮通信信息. 若攻击者多次阻断第2轮通信,则标签信息更新多次. 因为数据库预先存储了每个标签可能出现的信息,当FIP_Auth协议遭受异步攻击时,阅读器仍能对标签识别认证. 因此,FIP_Auth协议能抗异步攻击.
为了证明FIP_Auth协议具有前向隐私安全,首先证明关于伪随机数产生器G1和G2的一个结论:假设G=(GL, GR):\mathbb{Z}_{2}^{l \times n} \longrightarrow \mathbb{Z}_{2}^{l \times n+2 l},这里的G是伪随机数产生器G2,GL(·)代表G2输出的左边部分,GR(·)代表G2输出的右边部分. 对于任意的\boldsymbol{R} \in \mathbb{Z}_{2}^{l \times n},|GL(R)=l×n,|GR(R)=2l,则对于任意的\boldsymbol{x} \in \mathbb{Z}_{2}^{2 l},有|G1(x)|=L.
定理1 考察以下2个序列:
\begin{gathered} \bar{D}_{0}=\left\{G_{1}(\boldsymbol{x}), G_{1}\left(G_{\mathrm{R}}(\boldsymbol{R})\right), \cdots, G_{1}\left(G_{\mathrm{R}}^{n-1}(\boldsymbol{R})\right)\right\}, \\ \bar{D}_{1}=\left\{\boldsymbol{t}_{1}, \boldsymbol{t}_{2}, \cdots, \boldsymbol{t}_{n}\right\} . \end{gathered} 这里的t_{i} \stackrel{\$}{\leftarrow} \mathbb{Z}_{2}^{L} (i=1, 2, …, n),则D0与D1是计算不可区分的.
证明 假设D0与D1是计算可区分的,则可以构造一个算法B来区分伪随机数产生器G1的输出分布与均匀分布. 令y=(\boldsymbol{U}, \boldsymbol{v}) \in \mathbb{Z}_{2}^{l \times n+2 l},首先定义序列:
Y_{i}=\boldsymbol{t}_{1}, \cdots, \boldsymbol{t}_{i-2}, \boldsymbol{v}, G_{1}(\boldsymbol{v}), G_{1}\left(G_{\mathrm{R}}(\boldsymbol{U})\right), \cdots, G_{1}\left(G_{\mathrm{R}}^{n-i}(\boldsymbol{U})\right) 其中, i=2, \cdots, n ; \boldsymbol{t}_{j} \in \mathbb{Z}_{2}^{L}\;(j=1, 2, \cdots, i-2). 然后, 定义以下序列:
\begin{aligned} Y_{n+1} &=\left\{\boldsymbol{t}_{1}, \boldsymbol{t}_{2}, \cdots, \boldsymbol{t}_{n-1}, \boldsymbol{v}\right\}, Y_{n+2}=\left\{\boldsymbol{t}_{1}, \boldsymbol{t}_{2}, \cdots, \boldsymbol{t}_{n}\right\}=\bar{D}_{1}, \\ Y_{1} &=\left\{G_{1}(\boldsymbol{v}), G_{1}\left(G_{\mathrm{R}}(\boldsymbol{U})\right), \cdots, G_{1}\left(G_{\mathrm{R}}^{n-1}(\boldsymbol{U})\right)\right\}=\bar{D}_{0} . \end{aligned} 假设算法π是能以ε的优势成功区分序列D0和D1的多项式时间算法, 构造算法π参与的统计测试实验Epπi(y)(y=(U, v)):
(1) 按以上的定义构造Yi;
(2)b←π(Yi);
(3) 输出b.
令pi=Pr[Epπi(y)=1]. 算法B的执行过程如下:(1)接收伪随机数产生器的实验中的安全测试值y=(U, v);(2)随机选择一个i∈{2, …, n+2},进行统计测试的实验Epπi(y);(3)计算输出结果为序列D0的概率Pr[B(y)=1|y=G(R)]和序列D1的概率Pr[B(y)=1|y=t].根据区分序列D0与D1的概率, 得到伪随机数产生器G1的输出分布与随机分布是计算不可区分的.由于
\begin{array}{l} \Pr [B(y) = 1\mid y = G({\boldsymbol{R}})] = \left[ {\frac{1}{{n + 1}}} \right]\sum\limits_{i = 2}^{n + 2} {\Pr } \left[ {{\mathop{\rm Ep}\nolimits} _\pi ^iG({\boldsymbol{R}}) = 1} \right] = \\ \;\;\;[1/(n + 1)]\left( {{p_1} + {p_2} + \cdots + {p_{n + 1}}} \right) \end{array} \begin{array}{l} \Pr [B(y) = 1\mid y = t] = \left[ {\frac{1}{{(n + 1)}}} \right]\sum\limits_{i = 2}^{n + 2} {\Pr } \left[ {{\mathop{\rm Ep}\nolimits} _\pi ^i(t) = 1} \right] = \\ \;\;\;[1/(n + 1)]\left( {{p_2} + {p_3} + \cdots + {p_{n + 2}}} \right) \end{array} 所以,算法B区分序列D0与D1的概率为
\begin{gathered} |\operatorname{Pr}[B(y)=1 \mid y=G(R)]-\operatorname{Pr}[B(y)=1 \mid y=t]|= \\ {[1 /(n+1)]\left|p_{1}-p_{n+2}\right| \geqslant \varepsilon /(n+1), } \end{gathered} 则算法B区分伪随机数产生器G1的输出分布与随机分布的概率至少为ε/(n+1).证毕.
定理2 若G1和G2是2个伪随机数产生器,则FIP_Auth协议具有前向隐私安全性.
证明 要证明FIP_Auth协议的前向隐私性,需要证明2个标签行为的不可区分性. 构造2个序列D0与D1:
\begin{array}{l} {D_0} = {{\boldsymbol{a}}_1}, O\left( {{{\boldsymbol{a}}_1}, {{\boldsymbol{R}}_1}, {{\boldsymbol{x}}_1}} \right), {G_1}\left( {{{\boldsymbol{x}}_1}} \right), {{\boldsymbol{a}}_2}, O\left( {{{\boldsymbol{a}}_2}, {G_{\rm{L}}}\left( {{{\boldsymbol{R}}_1}} \right), {G_{\rm{R}}}\left( {{{\boldsymbol{R}}_1}} \right)} \right), \\ \;\;\;\;\;\;\;{G_1}\left( {{G_{\rm{R}}}\left( {{{\boldsymbol{R}}_1}} \right)} \right), \cdots , {{\boldsymbol{a}}_{\delta + 1}}, O\left( {{{\boldsymbol{a}}_{\delta + 1}}, G_{\rm{L}}^\delta \left( {{{\boldsymbol{R}}_1}} \right), G_{\rm{R}}^\delta \left( {{{\boldsymbol{R}}_1}} \right)} \right), \\ \;\;\;\;\;\;\;G_1^\delta \left( {G_{\rm{R}}^\delta \left( {{{\boldsymbol{R}}_1}} \right)} \right), {{\boldsymbol{b}}_1}, O\left( {{{\boldsymbol{b}}_1}, {{\boldsymbol{R}}_2}, {{\boldsymbol{x}}_2}} \right), {G_1}\left( {{{\boldsymbol{x}}_2}} \right), \\ \;\;\;\;\;\;\;{{\boldsymbol{b}}_2}, O\left( {{{\boldsymbol{b}}_2}, {G_{\rm{L}}}\left( {{{\boldsymbol{R}}_2}} \right), {G_{\rm{R}}}\left( {{{\boldsymbol{R}}_2}} \right)} \right), {G_1}\left( {{G_{\rm{R}}}\left( {{{\boldsymbol{R}}_2}} \right)} \right), \cdots , \\ \;\;\;\;\;\;\;{{\boldsymbol{b}}_{\lambda + 1}}, O\left( {{{\boldsymbol{b}}_2}, G_{\rm{L}}^\lambda \left( {{{\boldsymbol{R}}_2}} \right), G_{\rm{R}}^\lambda \left( {{{\boldsymbol{R}}_2}} \right)} \right), {G_1}\left( {G_{\rm{R}}^\lambda \left( {{{\boldsymbol{R}}_2}} \right)} \right);\\ {D_1} = {{\boldsymbol{a}}_1}, {{\boldsymbol{r}}_1}, {{\boldsymbol{t}}_1}, {{\boldsymbol{a}}_2}, {{\boldsymbol{r}}_2}, {{\boldsymbol{t}}_2}, \cdots , {{\boldsymbol{a}}_{\delta + 1}}, {{\boldsymbol{r}}_{\delta + 1}}, {{\boldsymbol{t}}_{\delta + 1}}, {{\boldsymbol{b}}_1}, {{\boldsymbol{u}}_1}, {{\boldsymbol{v}}_1}, \\ \;\;\;\;\;\;\;{{\boldsymbol{b}}_2}, {{\boldsymbol{u}}_2}, {{\boldsymbol{v}}_2}, \cdots , {{\boldsymbol{b}}_{\lambda + 1}}, {{\boldsymbol{u}}_{\lambda + 1}}, {{\boldsymbol{v}}_{\lambda + 1}}, \end{array} 其中,O表示输入为a、R和x且输出为\boldsymbol{R}^{\mathrm{T}} \cdot \boldsymbol{x}_{\downarrow a} \oplus \boldsymbol{e}的随机算法,这里e←Berτn; G_{\mathrm{L}}(\cdot) \in \mathbb{Z}_{2}^{l \times n}、G_{\mathrm{R}}(\cdot) \in \mathbb{Z}_{2}^{2 l}分别表示伪随机数产生器G2输出的左边部分、右边部分;R1, \boldsymbol{R}_{2} \in \mathbb{Z}_{2}^{l \times n};x1, \boldsymbol{x}_{2} \in \mathbb{Z}_{2}^{2 l};\boldsymbol{b}_{i} \stackrel{\$}{\leftarrow} \boldsymbol{\Omega};Ri, \boldsymbol{u}_{i} \stackrel{\$}{\longleftarrow} \mathbb{Z}_{2}^{n};ti, \boldsymbol{v}_{i} \stackrel{\$}{\longleftarrow} \mathbb{Z}_{2}^{k};δ、λ为自然数.
首先,证明序列D0与D1是计算不可区分的. 观察以下2个序列:
\begin{gathered} D_{0}^{\prime}=G_{1}\left(\boldsymbol{x}_{1}\right), G_{1}\left(G_{\mathrm{R}}\left(\boldsymbol{R}_{1}\right)\right), \cdots, G_{1}^{\delta}\left(G_{\mathrm{R}}^{\delta}\left(\boldsymbol{R}_{1}\right)\right), G_{1}\left(\boldsymbol{x}_{2}\right), \\ G_{1}\left(G_{\mathrm{R}}\left(\boldsymbol{R}_{2}\right)\right), \cdots, G_{1}\left(G_{\mathrm{R}}^{\lambda}\left(\boldsymbol{R}_{2}\right)\right) ; \\ D_{1}^{\prime}=\boldsymbol{t}_{1}, \boldsymbol{t}_{2}, \cdots, \boldsymbol{t}_{\delta+1}, \boldsymbol{v}_{1}, \boldsymbol{v}_{2}, \cdots, \boldsymbol{v}_{\lambda+1} . \end{gathered} 根据定理1可得D′0与D′1是计算不可区分的,证明方法与定理1类似,不再重复.
LPN假设指LPN输出结果\boldsymbol{R}^{\mathrm{T}} \cdot \boldsymbol{x}_{\downarrow a} \oplus \boldsymbol{e}的分布与均匀分布是计算不可区分的,则根据LPN假设可得序列
\begin{aligned} D_{0}^{\prime \prime}=& \boldsymbol{a}_{1}, O\left(\boldsymbol{a}_{1}, \boldsymbol{R}_{1}, x_{1}\right), \boldsymbol{a}_{2}, O\left(\boldsymbol{a}_{2}, G_{\mathrm{L}}\left(\boldsymbol{R}_{1}\right), G_{\mathrm{R}}\left(\boldsymbol{R}_{1}\right)\right), \cdots, \\ & \boldsymbol{a}_{\delta+1}, O\left(\boldsymbol{a}_{\delta+1}, G_{\mathrm{L}}^{\delta}\left(\boldsymbol{R}_{1}\right), G_{\mathrm{R}}^{\delta}\left(\boldsymbol{R}_{1}\right)\right), \boldsymbol{b}_{1}, O\left(b_{1}, R_{2}, \boldsymbol{x}_{2}\right), \\ & \boldsymbol{b}_{2}, O\left(\boldsymbol{b}_{2}, G_{\mathrm{L}}\left(\boldsymbol{R}_{2}\right), G_{\mathrm{R}}\left(\boldsymbol{R}_{2}\right)\right), \cdots, \boldsymbol{b}_{\lambda+1}, \\ & O\left(\boldsymbol{b}_{2}, G_{\mathrm{L}}^{\lambda}\left(\boldsymbol{R}_{2}\right), G_{\mathrm{R}}^{\lambda}\left(\boldsymbol{R}_{2}\right)\right) \end{aligned} 与
\begin{aligned} D_{1}^{\prime \prime}=& \boldsymbol{a}_{1}, \boldsymbol{r}_{1}, \boldsymbol{a}_{2}, \boldsymbol{r}_{2}, \cdots, \boldsymbol{a}_{\delta+1}, \boldsymbol{r}_{\delta+1}, \boldsymbol{b}_{1}, \boldsymbol{u}_{1}, \boldsymbol{b}_{2}, \boldsymbol{u}_{2}, \cdots, \\ & \boldsymbol{b}_{\lambda+1}, \boldsymbol{u}_{\lambda+1} \end{aligned} 是计算不可区分的.
综上,由于D′0与D′1是计算不可区分的,D″0与D″1是计算不可区分的,所以D0与D1是计算不可区分的.
然后, 使用反证法证明FIP_Auth协议的前向隐私安全. 假设FIP_Auth协议不具有前向隐私性,则存在一个能够在多项式时间内以不可忽略的优势ε攻击FIP_Auth协议的前向隐私的攻击者A. 假设攻击者A一共调用了q次预言机,则可以构造一个多项式时间算法ω来区分序列D0与D1.
算法ω的执行过程如下:
接收到测试序列(c1, z1, w1, c2, z2, w2, …, cδ+1, zδ+1, wδ+1, d1, s1, y1, d2, s2, y2, …, dλ+1, sλ+1, yλ+1) 后,首先,初始化(n-2)个标签,使用测试序列模拟对标签T1、T2的查询. 同时,选择一个随机数β∈{0, 1},令Tβ=T2,T1-β=T1;设置2个计数器k1和k2,初始值都设为1. 然后,分2个阶段执行. 在第一阶段,当攻击者A查询SendTag(sid, ck1, T1)时,返回zk1,并设置计数器k1=k1+1;当攻击者A查询SendTag(sid, dk2, T2)时,返回sk2,并设置计数器k2=k2+1. 在第二阶段,将Tβ交给攻击者A,当攻击者A查询Reveal(Tβ)时,直接返回dλ+1, sλ+1, yλ+1. 攻击者A输出一个随机数β′,若β=β′,则算法ω输出0, 表示测试序列来自D0;否则,输出1表示测试序列来自D1.
接下来分析算法ω的成功优势,分2种情况讨论.
情况1:测试序列来自D0. 因为算法ω模拟给攻击者A的环境与前向隐私游戏GameA的攻击环境完全一致,攻击者A能以不可忽略的优势ε攻击FIP_Auth协议的前向隐私,所以算法ω能以不可忽略的优势ε区分序列D0.
情况2:测试序列来自D1. 因为D1序列中的各个元素是相互独立和随机的,攻击者A只得到dλ+1、sλ+1、yλ+1,则无法获得ci、zi、wi、di、si、yi的任何有效信息,所以,攻击者A区分标签T1和T2的优势是可以忽略不计的.
综上,算法ω区分序列D0和D1的优势是不可忽略不计的,与序列本身的计算不可区分相互矛盾,因此,FIP_Auth协议具有前向隐私安全.
定理3 在LPN假设成立的前提条件下,FIP_Auth协议具有主动安全性.
FIP_Auth协议中包含识别部分与认证部分. 认证部分的设计与Auth协议是一致的;识别部分使用了伪随机数产生器G1和G2,利用伪随机数产生器G1的输出作为构建数据库的索引,G2用来更新标签的密钥信息(R, x).因此,对于FIP_Auth协议的主动安全证明与Auth协议的主动安全证明[5]是一致的,这里不再重复.
3.2 参数分析
对于FIP_Auth协议在参数的选择上,参数l, n \in \mathbb{N}是FIP_Auth协议中标签Ti存储的密钥信息(Ri, xi)的安全参数,\boldsymbol{R}_{i} \in \mathbb{Z}_{2}^{l \times n},\boldsymbol{x}_{i} \in \mathbb{Z}_{2}^{2 l}.τ∈[0, 1/2]是贝努利分布Berτ的参数,阅读器验证的阈值τ'∈[nτ, n/2]. 根据Auth协议和Auth#协议的参数选择,可以适当地选择FIP_Auth协议的相关参数. 设PFR表示错误拒绝水平,即合法标签被阅读器拒绝的可能性:
P_{\mathrm{FR}}=\sum\limits_{i=\tau^{\prime}+1}^{n}\left(\begin{array}{l} n \\ i \end{array}\right) \tau^{i}(1-\tau)^{n-i} ; (1) PFA表示错误接受水平,即非法标签被阅读器接受的水平:
P_{\mathrm{FA}}=\sum\limits_{i=0}^{\tau^{\prime}}\left(\begin{array}{l} n \\ i \end{array}\right) 2^{-n} (2) 由式(1)和式(2)可知,PFR、PFA均与密钥参数l的选择无关. 在HB协议与HB+协议中,式中的n为协议进行的轮数q.
由文献[3]知,协议每轮通信的安全水平至少为80 bit. FIP_Auth协议中第一轮的通信量最小,长度为2l,所以可以选取l=80, 以保证通信安全. 在贝努利参数τ为0.25和0.125的情况下,Auth协议和Auth#协议对安全参数l、n分别选取l=80、n=1 164和l=80、n=441. 选取FIP_Auth的参数(表 1)如下:
表 1 FIP_Auth协议的参数集Table 1. The parameter sets of the FIP_Auth protocol参数集 l n τ τ' PFR PFA 1 80 1 164 0.250 405 2-45 2-83 2 80 441 0.125 113 2-45 2-83 (1) 参数集1:当协议的安全水平为l=80, n=1 164时,贝努利参数τ为0.25,则阅读器验证的阈值τ′的取值范围为[0.25n, n/2],从而适当地选取τ',计算PFR和PFA.
(2) 参数集2:当协议的安全水平为l=80, n=441时,贝努利参数τ为0.125,则阅读器验证的阈值τ'的取值范围为[0.125n, n/2],从而适当地选取τ',计算PFR和PFA.
3.3 4个协议的对比分析
本节主要将FIP_Auth协议与Tree-LSHB+、BAJR、MMR协议的隐私性、安全性、轮数、通信复杂度、标签计算复杂度和密钥大小进行对比.
由结果(表 2)可知:(1)虽然4个协议均考虑了隐私性,但只有FIP_Auth协议与BAJR协议具备隐私性.(2)虽然BAJR协议达到一般中间人安全,而FIP_Auth协议只达到主动安全,但是FIP_Auth协议的通信轮数只需2轮且通信量更低. 而且,BAJR协议执行时,标签需要计算3次哈希函数,使得无法实现标签的低成本且计算复杂度高;FIP_Auth协议执行时,标签只进行异或计算,计算复杂度低且实现了标签低成本.
表 2 4个RFID认证协议的效率与安全比较Table 2. The comparison of efficiency and security of 4 RFID authentication protocols协议 隐私性 安全性 轮数 密钥大小 识别时间 通信量 计算复杂度 Tree-LSHB+ 不具备 抗主动攻击 3 2l O(log NT) (l×n+n)d+2(l×n)+2n O(l) BAJR 具备 抗一般中间人攻击 3 l O(1) l+5h(·) 3Thash MMR 不具备 抗一般中间人攻击 3 l×n O(1) 4l+l2+3n O(l) FIP_Auth 具备 抗主动攻击 2 2l O(1) 2l+n+L O(l) 注:Thash是BAJR协议中标签计算1次哈希函数所需要的时间,h(·)表示哈希函数运算输出的长度. 4. 结束语
本文在Auth协议的基础上,借鉴SFP通用构造协议的设计方法,利用基于LPN设计的伪随机数产生器以及RFID系统中原有的大型存储设备数据库,设计具有快速识别的隐私保护认证协议(FIP_Auth). 与Tree-LSHB+、BAJR、MMR协议相比,FIP_Auth协议具有较小的密钥存储、较低的通信量,最重要的是标签的识别速度达到了O(1),并且保证了协议的隐私安全.
但是,FIP_Auth协议只达到了抗主动攻击,不能抵抗一般中间人攻击. 设计具有与FIP_Auth协议一样的优势并且能抗一般中间人攻击的协议是下一步的研究重点.
-
![]()
图 1 RFID系统的数据库初始化所需的索引值表
Figure 1. The table of index value required for RFID system database initialization
![]()
图 3 RFID认证协议FIP_Auth的执行过程
Figure 3. The implementation process of RFID authentication protocol FIP_Auth
表 1 FIP_Auth协议的参数集
Table 1 The parameter sets of the FIP_Auth protocol
参数集 l n τ τ' PFR PFA 1 80 1 164 0.250 405 2-45 2-83 2 80 441 0.125 113 2-45 2-83  下载: 导出CSV
下载: 导出CSV
表 2 4个RFID认证协议的效率与安全比较
Table 2 The comparison of efficiency and security of 4 RFID authentication protocols
协议 隐私性 安全性 轮数 密钥大小 识别时间 通信量 计算复杂度 Tree-LSHB+ 不具备 抗主动攻击 3 2l O(log NT) (l×n+n)d+2(l×n)+2n O(l) BAJR 具备 抗一般中间人攻击 3 l O(1) l+5h(·) 3Thash MMR 不具备 抗一般中间人攻击 3 l×n O(1) 4l+l2+3n O(l) FIP_Auth 具备 抗主动攻击 2 2l O(1) 2l+n+L O(l) 注:Thash是BAJR协议中标签计算1次哈希函数所需要的时间,h(·)表示哈希函数运算输出的长度.
下载: 导出CSV
-
[1] BLUM A, FURST M, KEARNSM, et al. Cryptographic pri-mitives based on hard learning problems[C]//Advances in Cryptology-CRYPTO'93. Berlin: Springer, 1993: 278-291.
[2] HOPPER N J, BLUM M. Secure human identification protocols[C]//Advances in Cryptology-ASIACRYPT 2001. Berlin: Springer, 2001: 52-66.
[3] JUELS A, WEIS S A. Authenticating pervasive devices with human protocols[C]// Advances in Cryptology-CRYPTO 2005. Berlin: Springer, 2005: 293-308.
[4] GILBERT H, ROBSHAW M J B, SEURIN Y. Increasing the security and efficiency of HB+[C]//Advances in Cryptology-EUROCRYPT 2008. Berlin: Springer, 2008: 361-378.
[5] KILTZ E, PIETRZAK K, VENTURI D, et al. Efficient authentication from hard learning problems[C]//Advances in Cryptology-EUROCRYPT 2011. Berlin: Springer, 2011: 7-26.
[6] RIZOMILIOTIS P, GRITZALIS S. Revisiting lightweight authentication protocols based on hard learning prob-lems[C]//Proceedings of the Sixth ACM Conference on Security and Privacy in Wireless and Mobile Networks. New York: ACM, 2013: 125-130.
[7] 姜晓, 马昌社. 基于LPN抗中间人攻击的两轮认证协议[J]. 华南师范大学学报(自然科学版), 2016, 48(3): 64-68. doi: 10.6054/j.jscnun.2016.05.005 JIANG X, MA C S. MIM secure two-round authentication protocols based on LPN[J]. Journal of South China Normal University(Natural Science Edition), 2016, 48(3): 64-68. doi: 10.6054/j.jscnun.2016.05.005
[8] 卿哲嘉. 基于LPN具有一般中间人安全的两轮认证协议[J]. 计算机工程, 2019, 45(2): 129-133. https://www.cnki.com.cn/Article/CJFDTOTAL-JSJC201902021.htm QING Z J. General MIM secure two-round authentication protocol based on LPN[J]. Computer Engineering, 2019, 45(2): 129-133. https://www.cnki.com.cn/Article/CJFDTOTAL-JSJC201902021.htm
[9] DAS M L, KUMAR P, MARTIN A. Secure and privacy-preserving RFID authentication scheme for internet of things applications[J]. Wireless Personal Communications, 2020, 110(1): 339-353. doi: 10.1007/s11277-019-06731-1
[10] AVOINE G, DYSLI E, OECHSLIN P. Reducing time complexity in RFID systems[C]//Selected Areas in Crypto-graphy. Berlin: Springer, 2005: 291-306.
[11] LU L, HAN J, HU L, et al. Dynamic key-updating: privacy-preserving authentication for RFID systems[J]. International Journal of Distributed Sensor Networks, 2012, 8(5): 13-22. http://www.greenorbs.org/people/liu/SPA.pdf
[12] LU L, HAN J, XIAO R, et al. ACTION: breaking the privacy barrier for RFID systems[C]//Proceedings of International Conference on Computer Communications. Brazil: IEEE, 2009: 1953-1961.
[13] DENG G, LI H, ZHANG Y, et al. Tree-LSHB+: an LPN-based lightweight mutual authentication RFID protocol[J]. Wireless Personal Communications, 2013, 72(1): 159-174. doi: 10.1007/s11277-013-1006-2
[14] ALOMAIR B, CLARK A, CUELLAR J, et al. Scalable RFID systems: a privacy-preserving protocol with constant-time identification[J]. IEEE Transactions on Parallel and Distributed Systems, 2011, 23(8): 1536-1550.
[15] MAMUN M S I, MIYAJI A, RAHMAN M S. A secure and private RFID authentication protocol under SLPN problem[C]//Proceedings of the 6th International Conference on Network and System Security. Berlin: Springer, 2012: 476-489.
[16] 马昌社. 前向隐私安全的低成本RFID认证协议[J]. 计算机学报, 2011, 34(8): 1387-1398. https://www.cnki.com.cn/Article/CJFDTOTAL-JSJX201108006.htm MA C S. Low cost RFID authentication protocol with forwardprivacy[J]. Chinese Journal of Computers, 2011, 34(8): 1387-1398. https://www.cnki.com.cn/Article/CJFDTOTAL-JSJX201108006.htm
[17] BERLEKAMP E, MCELIECE R, VAN TILBORG H. On the inherent intractability of certain coding problems[J]. IEEE Transactions on Information Theory, 1978, 24(3): 384-386. doi: 10.1109/TIT.1978.1055873
[18] NOMAGUCHI H, SU C, MIYAJI A. New pseudorandom number generator for EPC Gen2[J]. IEICE Transactions on Information and Systems, 2020, 103(2): 292-298. http://www.researchgate.net/publication/338978473_New_Pseudo-Random_Number_Generator_for_EPC_Gen2
[19] APPLEBAUM B, ISHAI Y, KUSHILEVITZ E. On pseudorandom generators with linear stretch in NC0[J]. Computational Complexity, 2008, 17(1): 38-69. doi: 10.1007/s00037-007-0237-6
[20] MOSSEL E, SHPILKA A, TREVISAN L. On ε-biased generators in NC0[J]. Random Structures & Algorithms, 2006, 29(1): 56-81. doi: 10.1002/rsa.20112/abstract

计量
- 文章访问数: 433
- HTML全文浏览量: 127
- PDF下载量: 47
